





gooブログをStarServerへお引越し!-その4 データを落とす
続いて、gooブログからデータを落とすが滅茶滅茶面倒!というお話。
***後から思うと、この前に https化 をここでやっておくべきだったと後悔しています***
HTTPS化する! その1/2 、 HTTPS化する! その2/2 を参照ください
そもそも、gooブログのデータは、無料会員だと落とせない。アドバンス以上じゃないとダメ。私はアドバンス会員なのでOK。入会してすぐ脱会すればなんとかなるらしいけど。
管理ページの、
バックアップ・書籍化をクリック。
作成するを押して、しばらく待つと、データがダウンロードできるようになる。私の場合1時間位。
ここからは、ネット情報を活用します!アジアン ライフさんやもじぐみさんありがとうございます!
まずエディタがいる。DreamWeaverというのが紹介されてるけど、無料のエディタで済ませたい(^^;)
サクラエディタというのをダウンロードしてみた。
こんな感じ。
これにgooブログからダウンロードしたファイルを入れると、
こんな感じになる。ふと、右下隅を見ると、
あれ?! 元々UTF-8なんじゃないか?何もしなくていいのでは・・・
そう思いつつ名前を替えて保存しようとしたら、
こんな画面が出た。BOMにチェックが入っていないのを見つつ保存した。
後でさらに色々やってみたら、Windows10のメモ帳で開いてから保存しようとすると、
こんな感じでUTF-8と出るので、メモ帳でも対応できるようだが、メモ帳で保存したものを サクラエディタで開くと、BOM付と出る?!なんだこれ?
調べると、BOM付だと色々トラブル発生するらしく、次のメモ帳ではBOM無しが標準になるらしい。
たぶん、今のところエディタでBOM無しのUTF-8にした方がいいんじゃないかな。(メモ帳では試していません)
面倒なのは、この変換済みデータの 例えば、
<p><img src=”https://blogimg.goo.ne.jp/user_image/51/cc/42c105c0181fc90cf0eae035843c0002.jpg”
の「https://blogimag.goo.ne.jp/user_image/51/cc/」の部分を引っ越し先の保管場所に変更する必要あるはずだが、なんちゅうところに保管されるんだろう?まだ調べていませんm(_ _)m
なのでこのデータはまだ未完成!です・・・その6に続きがあります
■ワードプレスにgooと同じカテゴリを作成する
ここを参考にさせて頂きました!ありがとうございます!
ワードプレスの管理画面から、カテゴリーを選択し、名前を付けていく。
こんな感じ。
ホントはこれを機会に階層分けとかしたらいいのかも知れないが、とりあえずgooブログと同じに。
スラッグというのは、カテゴリーのある場所のことらしく、漢字かなは不可らしい。
カテゴリー:文具 で スラッグ:goods と設定すると、
というところに保存されることになるらしいので、それなりに大事だ。
とりあえず21カテゴリー・・・一通り作ってみた。
次に、
absurlをダウンロード。Vectorからいただきましたm(_ _)m
これにgooからダウンロードしたテキストファイルを入れて、画像のURLを抽出する。
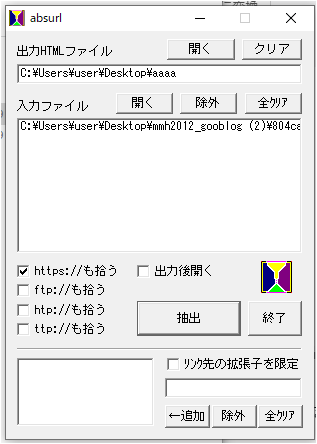
出力HTMLファイルは適当な名前を付ける。入力ファイルはgooブログからダウンロードして解凍したtxtファイル。抽出を押して終了を押して完了のようだ。素晴らしい!
そうしたら、サクラエディタを起動し、出来たファイル(上の例ではaaaa)をエディタにドラッグ&ドロップ。
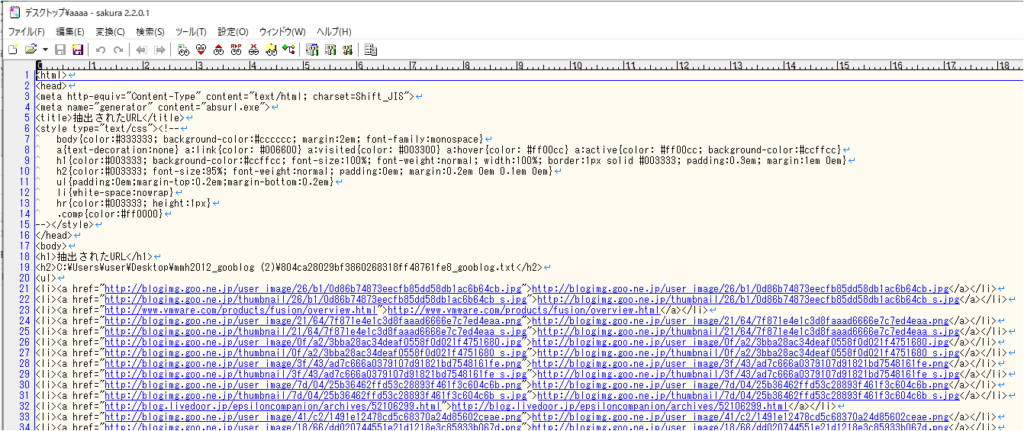
こんな感じです。いらないヤツも結構残るので、チマチマ30分位かけて消したら、残りは1800行!大変だ・・・
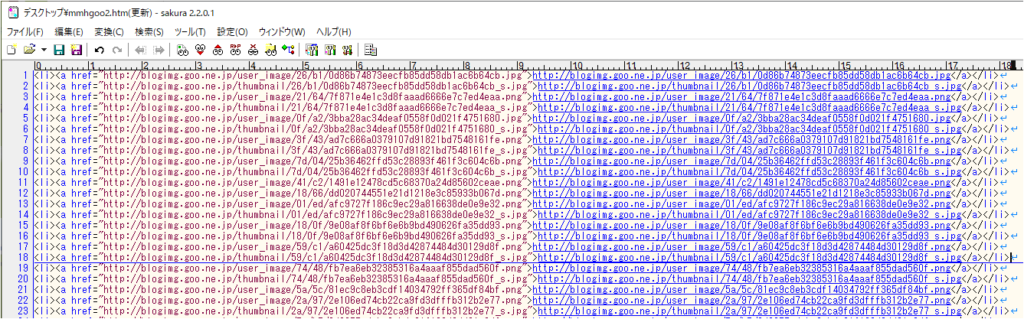
最後が jpg とか png だけを残して他は消しました。でも・・・2重なんだなぁ。これでいいのか?
(2重なのは、gooブログが小さい画像(サムネイル)と大きな画像を用意している為でした)
(今回は、ほぼほぼ小さい画像を無視しました)
更に皆さんの通り、IrvineというソフトをVectorからダウンロードm(_ _)m
上で作ったURLから画像を一括でダウンロードするものらしい。上のファイルをインポートする。
ところが、これが全然上手くいきません!タイムアウトで全然だめ。最初は分からなかったけど、
どうやらHTLMタグがあるとダメみたいで、
しかも、
<li><a href=”https://blogimg.goo.ne.jp/user…‥.jpg”>https://blogimg.goone.jp/user‥…</a></li>
のようにダブっているのもダメみたい。これをサクラエディタでどうやって取り除くのかわからず・・・
そこで、サクラエディタでテキストファイルにして、
エクセルで読み込んでみた。この際、 > を区分けに利用する設定にしたら、
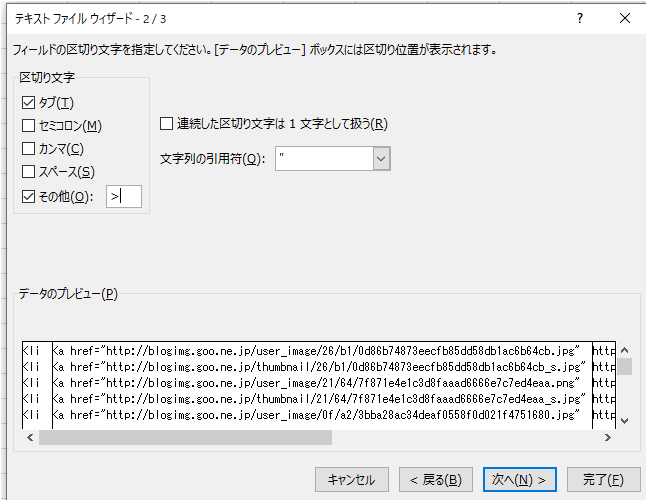
<li と <a href=….jpg” と https://blog・・・・</a と </li に分かれた!

要らないA、B、D列を消し、
LEFT関数を使い =LEFT(A221,LEN(A221)-3) として、右側3文字を消去。 </a の3文字を抜いて、 https://blog・・・ だけを抜き出すことに成功!

ここで、B列をコピーして新しいエクセルに「値」として貼り付け、さらにコピー&ペーストでサクラエディタに戻し、テキストで保存する。
それをIrvineのインポート→URLリスト から読み込むと・・・いきなりダウンロードが始まりました!!
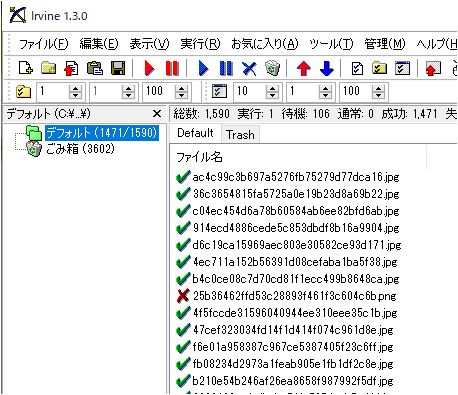
これ、エクセル上でちょっと弄ると上手く変換できないみたい。3文字消したやつを新しいエクセルシートにテキストでペーストし、更にコピーしてエディタに貼り、これをテキストで保存したやつをIrvineに読み込むと上手く行きました!とても不思議です。
なぜか読み込めないファイルもあるけど、細かいことは気にしない。時間がすごくかかって、1590個の画像ファイルを1時間くらいかな。
1590ファイルで読み込めないものが13個。理由は不明。もともと無かったのか・・・
とりあえず、テキストデータと画像ファイルがパソコンにダウンロードできました。
疲れます・・・

